


Dear friend,
«Why has it stopped working? Why can’t I configure this feature? What the hell is going on here? » I’m almost sure that you are familiar with situations when known technologies stop operating at all. Or even worse, they stop operating as proper and start operating false. In this notice I’d share my ideas about troubleshooting and related items.
What is troubleshooting about?
If you are sick, you usually go to a doctor. You describe your problems, and then the doctor examines you and provides you some treatment. That is actually the troubleshooting.
Let’s transfer this example to the networking field. One of the crucial parts of the responsibilities of any network engineer is to fix the problem and eliminate its root cause if something breaks. If we talk about Operations, meaning the people who constantly support the network, such responsibilities will be the most important for them. As with any other work, having experience is quite good and useful as you can easily and quicker resolve the issues. But what should you do, if you are just young and green? There is just one way, which is actually gathering the experience. I’d like to share with you some guidelines that I’ve created from my own experience and experience of my colleagues. There are three main ideas which build the foundation of the troubleshooting. Everything other you will collect and develop yourself if you have this foundation. It’s not occasionally and it’s so important that Cisco has a separate exam for troubleshooting at CCNP level and two parts in lab exam at CCIE level, which cover only troubleshooting of network scenarios.
First of all is Understanding
Understanding or knowledge means that you understand how each certain technology works and how it relates to other technologies. Let’s say you are troubleshooting redundant layer 2 network. It’s about 90% that you will deal with STP, so you need understand how Root Bridge is elected, how root/designates/blocked ports are elected and how such topology is maintained or rebuilt. There is also possibility more than 90 percent that you will also meet some kind of etherchannels (port-channels or LAG), so you have to know how it can be formed (PAgP, LACP, static) and how load-sharing is achieved across links. All this information is widely available in the Internet, but the in emergency case you might have no time to look it for. That’s why here very important to have the knowledge in the head, and only in the Internet.
Real world scenario #1
The last week I’ve troubleshooted interesting case. We were in the process of migrating on the new provider-independent IP addresses, so we were making IP renumbering for our servers. Everything was pretty well besides just one server. There was about 50 percent packet loss to its new IP address, whereas there was no packet loss to its old IP. From the network topology perspectives we have 2 edge routers connected to the ISP in a dual-homed manner. Both links had equal bandwidth, so the ISP on its side configured BGP multipathing in order to share load. I didn’t know exactly the load sharing algorithm that was used by ISP, but the suspicions fell on my edge routers. Roughly said it looked like the half of the traffic passing by one router was dropped. I checked the routing table on both the routers and found that on one of them there was configured loopback interface with IP of the server. As I cleared later, a colleague of mine had configured it at the beginning of IP renumbering for test purposes and had forgotten to remove it. So understanding of both load sharing and potential influence of traffic path on its delivery helped me to find the router that dropped my traffic.
The second point is Baselining
It is insufficient to understand technologies only. If must be aware of context, where the technologies work. As it was in my previous example, I knew that upstream used BGP multipath. This information helped me to make an assumption which was correct. In general baselining means documentation of the network’s behavior, like traffic pattern across the day, chose of active/standby links and so on. If you experience the abnormal behavior it makes sense to check it. For example, in redundant layer 2 network you have noticed that at the access switches there designated and alternate ports are changed. Speaking in ITIL language you are facing an event, what is significant deviation from normal behavior. Change in ports role may mean that you have another switch acting as the root bridge instead of planned one. Or maybe some 1Gig SFPs were swapped with 10Gig SFPs what led RPC (root path cost) recalculation. That’s why baselining or documenting normal network behavior is crucial for troubleshooting as it’s really hard to say whether you experience problem in your network if you can’t compare it with something.
Real world scenario #2
A couple of month ago I led the project, which aim was the swap of old Cisco ASA 5500 series with new Cisco ASA 5500-X series. ASAs played role of VPN head-end, so their main task was to terminate IPSec VPNs. The main issue with migration was that new ASAs had new public IP addresses so it wasn’t possible just to replace the box. It was necessary to migrate all VPNs one by one on the new ASA cluster. From the network topology perspective both ASA clusters were connected to the same aggregation level routers. At these routers there were static routes pointing to the range of customer networks in direction of old ASA cluster, we decided to establish dynamic routing between new ASA cluster and distribution routers and redistribute more specific routes from that new ASA cluster. Such approach provided us possibility to make the migration seamless. At Cisco devices like ASA or routers the redistribution of VPN routes can be done if you configure reverse-route injection for crypto-map. But there is a difference in operation of this feature at Cisco routers and ASAs. At router reverse-route injection feature installs route only if VPN is active, whereas at ASA it installs route if VPN is just configured. It’s possible to make the same configuration at routers as well, but usually it isn’t necessary. Our supplier who performed this migration wasn’t aware of this difference and activated reverse-route injection for all policies at the new Cisco ASAs cluster. It led to the following situation:
- At the new ASAs cluster all the more-specific routes were installed in the routing table (RIB) and redistributed into routing protocol.
- By that routing protocol these more-specific routes were delivered to the distribution routers and installed in the RIB there.
- VPNs were active at the old ASA cluster, because no VPNs were reconfigured at the customer side in order to connect to the new Cisco ASA cluster.
- We got the asymmetrical routing, where traffic came from the old ASA cluster to distribution routers but in back direction went it to the new ASA cluster.
As no VPNS were down, network management system didn’t show alarms, but the analysis of VPNs utilization shew that there was only incoming traffic in VPNs without outgoing. Such behavior is definitely abnormal, so I checked the RIB at distribute routers and found the issue. Then the reverse route injection was deactivated for all crypto-maps at the new Cisco ASAs cluster and the proper operation was restored.
The last but not least is Courage
Troubleshooting often deals with a high degree of uncertainty. There are always too many things that can be broken and there are too many ways to fix something as well. In such environment courage is the critical ability that helps you to make a decision, implement it and be responsible for it. You must be ready that your solution can do harm especially at the beginning of your career. But for sure the absence of any rescuing actions for your network is much more harmful. If something goes wrong, there is too little chance that it will restore itself without corrective actions. First of all you should implement workaround solution to eliminate or limit the impact of failure of your system. Then you should find the root cause and eliminate it completely. There is often not enough time to double check solution for workaround. So the best way is to check a couple of assumptions and implement them. With the growth of your experience your assumptions will be more accurate from the very beginning.
Real world scenario #3
The last week I’ve made a short disruption in the production network during fixing the long-term problem with our servers. The problem was so that after reboot of the VMs the windows wasn’t able to pass duplicate address detection (DAD) and the service wasn’t available. The problem is good described at the official Cisco web-site (here http://goo.gl/JVK5fk and http://goo.gl/mgVyQT), so I won’t copy paste this information. The real root cause for the problem was that we are unaware of the fact that feature IP Device Tracking was on be default and it influenced the whole network as the STP root bridge was the device that has IP Device Tracking. But after I’ve made some troubleshooting, we’ve found the solution to eliminate this problem by changing physical connectivity in our switched (layer 2) part of network. Without such disruption it was almost impossible.
What to do next
Well, we’ve spoken about main skills that are related to troubleshooting process. Now I’ll provide you with three the most important guidelines that will incredibly help you:
- Implement workaround. Just remember that first of all you need to restore the operation of the network at satisfactory level. After the restoration is done you can proceed with root cause analysis, simulation and making the solution to address it.
- Use Cisco Bug Tracking Tool. The probability is nearly zero that your bug is unique. So use this Cisco’s tool to find your problem, workaround and solution much faster. Here it is: https://tools.cisco.com/bugsearch/. If you use other vendors, I suppose that they also have such tool.
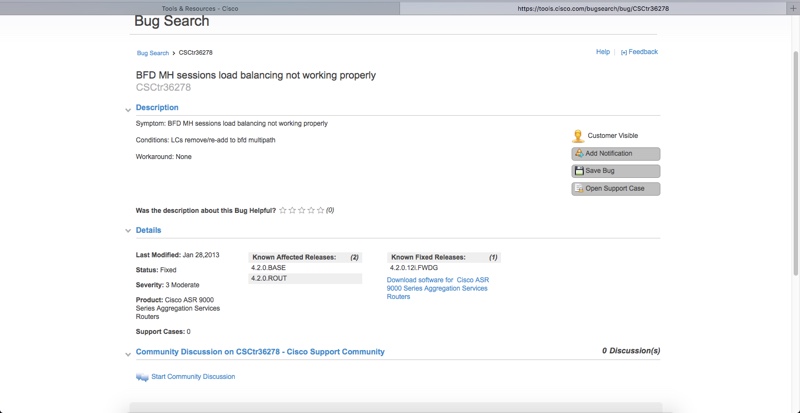
- Use Cisco Release Notes. For each version of software for each Cisco product there is a documentation that describes changes in operation and supported technologies. It might be that your solution doesn’t work because it isn’t supported in the certain version. Example: http://goo.gl/pRvJgy


Lessons learned
For me the lessons learned were always to read myself and to make my colleagues read release notes prior to implement anything. The main issue here is that you can be not the only engineer in the company. It leads to the situation that something can be implemented without you awareness what increase degree of uncertainty in the network.
Conclusions
It’s better to do something and fail than not to do anything. Without fixing problems it’s impossible to develop troubleshooting skills. Don’t avoid troubleshooting something by transferring this task to your colleagues.