


Hello my friend,
Very often at our zero-to-hero network automation training we are asked, what is the benefit of Bash? Why do we need to know Bash, if everyone is talking about Bash? The question is absolutely legitimate. One of the interesting and also legitimate answers I’ve just figured the last week.
2
3
4
5
retrieval system, or transmitted in any form or by any
means, electronic, mechanical or photocopying, recording,
or otherwise, for commercial purposes without the
prior permission of the author.
Do you finally write about network automation?
Everything in your network and IT operational processes can be automated. It is just matter of the resources (time, money, efforts) you spent on that against the gain you are obtaining. Basically, that is something what financial guys and girls call ROI (Return On Investments). The bigger the outcome and the lower the effort, the better the overall automation solution.
In our automation trainings we explain various use cases and success (and failure) strategies, how to build the (network) automation systems and tools, to make sure your gain is maximum. Our instructors have an extensive experience building such solutions in a high-scale environment of service providers, enterprises, data centre and clouds. Therefore, attending our trainings will give you a real world experience of building (network) automation, which would help you to make your tasks quicker and more efficient. Some students are even taking the examples from our training use them directly, what speaks for the quality of the materials.
Brief description
So, going back to the original question “Why do I need to know Bash?” Answer to the question is very simple: everywhere, where you have any Linux distribution (or Unix and even MacOS), you can benefit from the Bash directly out of CLI. In fact, the only Linux distribution, which doesn’t have Bash by default from all Linux distributions I’ve seen so far is Alpine Linux. However, we can forgive that for the Linux with size just over 5 MB.
In our zero-to-hero network automation training we teach you how to create applications with Bash and show a lot of real-life use cases.
There are a few common misbeliefs:
- Bash is old. Well, It is not older than BGP: first version on Bash and of BGP were created in June 1989. No one though says that BGP is too old to be used in the network, because BGP is being continuously developed with new address-families (e.g., IPv6 Unicast, VPNv4 and VPNv6, Multicast VPN, EVPN) and functionality improvements (e.g., PIC – prefix-independent convergence, A-IGP and Segment Routing). Same is happening with Bash: the latest release Bash 5.0 was release just in 2019.
- Bash is not functional. That comes often from people, who don’t really know what Bash is, how it works or just thinking that Bash syntax is too strange.
None of those misbeliefs is, as you see, accurate. Moreover, if you used Bash even a bit yourself in past few years, you understand how far from the reality those statements are.
The best quote we’ve heard from our students about Bash was: “I’ve studied Bash in depth in Uni, I’ve written my thesis about Bash, I have no clue I can achieve that much what you show me.”
You can think that this statement is overreaction; however, as you are about to see, there are really a lot of use from Bash for troubleshooting Linux. Let’s take a look on two use cases:
- Measuring the packet loss
- Collating the simple view of the information
#1. Measuring packet loss
The first use case is to measure a packet loss and/or reachability towards a certain hosts. Some time ago we shew an fping and how it could help to verify if hosts are reachable. However, it doesn’t measure a packet loss. After some investigations, we figured out that is possible to run a rapid ping with interval just 0.2 or 0.1 seconds using an ordinary Linux ping:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
PING 1.1.1.1 (1.1.1.1): 56 data bytes
64 bytes from 1.1.1.1: icmp_seq=0 ttl=58 time=5.500 ms
64 bytes from 1.1.1.1: icmp_seq=1 ttl=58 time=4.908 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=58 time=5.087 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=58 time=5.422 ms
64 bytes from 1.1.1.1: icmp_seq=4 ttl=58 time=5.040 ms
64 bytes from 1.1.1.1: icmp_seq=5 ttl=58 time=4.529 ms
64 bytes from 1.1.1.1: icmp_seq=6 ttl=58 time=4.732 ms
64 bytes from 1.1.1.1: icmp_seq=7 ttl=58 time=5.413 ms
64 bytes from 1.1.1.1: icmp_seq=8 ttl=58 time=5.311 ms
64 bytes from 1.1.1.1: icmp_seq=9 ttl=58 time=5.260 ms
64 bytes from 1.1.1.1: icmp_seq=10 ttl=58 time=4.925 ms
64 bytes from 1.1.1.1: icmp_seq=11 ttl=58 time=4.344 ms
64 bytes from 1.1.1.1: icmp_seq=12 ttl=58 time=4.867 ms
64 bytes from 1.1.1.1: icmp_seq=13 ttl=58 time=4.610 ms
64 bytes from 1.1.1.1: icmp_seq=14 ttl=58 time=5.449 ms
64 bytes from 1.1.1.1: icmp_seq=15 ttl=58 time=4.831 ms
64 bytes from 1.1.1.1: icmp_seq=16 ttl=58 time=5.426 ms
64 bytes from 1.1.1.1: icmp_seq=17 ttl=58 time=4.892 ms
64 bytes from 1.1.1.1: icmp_seq=18 ttl=58 time=9.760 ms
64 bytes from 1.1.1.1: icmp_seq=19 ttl=58 time=4.407 ms
--- 1.1.1.1 ping statistics ---
20 packets transmitted, 20 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 4.344/5.236/9.760/1.095 ms
It looks just 2-4 seconds to send 20 requests and receive the corresponding responses. If there is somewhere a congestion or ARP issues, then you can quickly spot that.
You may think, OK, what’s the point of mentioning Bash then?..
Well, what if you need to do that for multiple hosts. Say, 30 hosts? Also, how to get he output in somewhat easy processable format? Say, CSV? Here is where Bash comes to the stage.
First of all, let’s create our input file with IP addresses we are willing to test. It is created in a simple format: one line per IP address:
2
3
4
5
6
7
8
1.1.1.1
2.2.2.2
3.3.3.3
!
! SOME OUTPUT IS TRUNCATED FOR BREVITY
!
31.31.31.31
Now let’s create Bash script. Also it is worth to outline, we’d like to create a Bash script, which is platform neutral: it means it can work both on Linux and MacOS systems:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
OUTPUT="results.csv"
INTERVAL="0.1"
COUNT="20"
echo "host_ip,packet_loss" > "${OUTPUT}"
SYSTEM_TYPE=$(uname)
while read LINE; do
echo "Checking packet loss for ${LINE}..."
if [[ ${SYSTEM_TYPE} == "Linux" ]]; then
PACKET_LOSS=$(ping ${LINE} -c ${COUNT} -i ${INTERVAL} | awk '/loss/ {print $6}')
else
PACKET_LOSS=$(ping ${LINE} -c ${COUNT} -i ${INTERVAL} | awk '/loss/ {print $7}')
fi
echo "${LINE},${PACKET_LOSS}" >> "${OUTPUT}"
done < ${1}
What’s happening here:
- We set some variables, such us the name of the result file, ping interval and amount of pings per destination host.
- We create a loop over the input IP addresses. Inside the loop we perform the ping operation, search for the line containing the packet loss information and extracts the output there.
- The information is parsed based on the platform type, as for MacOS and for (Cumulus) Linux the different columns are to be extracted.
- The output is saved in csv format: ip_target, packet_loss.
Let’s run the script:
2
3
4
5
6
7
8
Checking packet loss for 1.1.1.1...
Checking packet loss for 2.2.2.2...
Checking packet loss for 3.3.3.3...
!
! SOME OUTPUT IS TRUNCATED FOR BREVITY
!
Checking packet loss for 30.30.30.31...
The result is collected in the results.csv file:

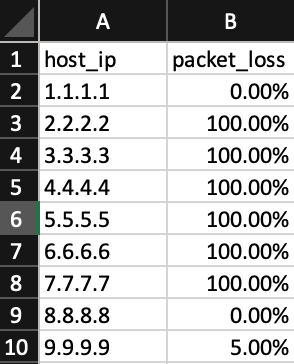
This data is already easy visually understandable by people; it is simple to parse it with Python or Ansible and also It is collected for a list of IPs in an automated way.
At our zero-to-hero Network Automation Training you will learn a lot more Bash tricks and use cases.
#2. Collating the information
Another good example of Bash is also related to the Linux. Recently we were troubleshooting the Cumulus Linux and needed to quickly solve such a task:
- Take the IP address(es) of the host connected to the data centre fabric as an input
- Find the MAC addresses associated with the IP addresses
- Find the VLAN and VNI the the IP address belongs to
- Find the VTEP IP address, where the IP/MAC is located.
The input format would be the same as in the previous examples:
2
3
4
5
192.168.1.10
192.168.1.20
192.168.3.30
192.168.4.40
The Bash script, which you need to run on Cumulus Linux host is very simple:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#!/usr/bin/env bash
OUTPUT="results.csv"
echo "host_ip,host_mac,host_vlan,switch_lo_ip" > "${OUTPUT}"
while read LINE; do
echo "Looking for destination for ${LINE}..."
MAC_ANSWER=($(ip -4 neighbor | grep "^${LINE}\s" | awk '{print $5, $3}'))
SWITCH_IP=$(net show bridge macs | grep "untag.*${MAC_ANSWER[0]}" | awk '{print $4}')
echo "${LINE},${MAC_ANSWER[0]},${MAC_ANSWER[1]},${SWITCH_IP}" >> "${OUTPUT}"
done < ${1}
What is happening here:
- the input file containing one IP address per line is taken.
- going line by line we are collecting info MAC and VLAN using ip -4 neighbor command and awk parser.
- collect information about MAC to VTEP mapping using net show bridge macs command and awk parser.
- Save the output in the csv file.
Let’s run the script:
And the result:

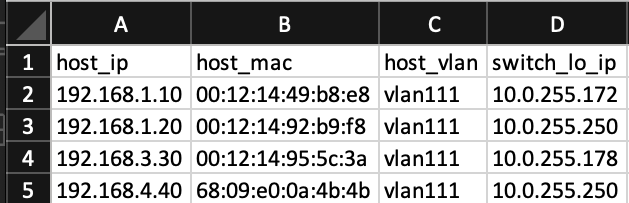
Again, you could see nice and simple csv table output. The one could say, that it is more preferable to have the JSON or YAML (though it is possible as well); however, for humans per our observations spreadsheets are easier to consume.
At our zero-to-hero network automation training we explain to you how to deal with JSON and YAML data formats in Bash.
GitHub repo
You may find this an other examples of automated troubleshooting at our GitHub.
Take me to the examplesLessons learned
One of the key aspect of developing the multi platform Bash scripts is to thoroughly validate the output format. Often, you might find small discrepancies in the outputs of the same command between MacOS and Linux. As this might affect the ultimate result of your Bash tool, make sure your parse is flexible enough to take this differences in account whilst rendering results.
Conclusion
Bash is very useful tool to have under your belt for automation of any Linux and MacOS activities. And as Linux is conquering the networking space with Cumulus Linux or SONiC operating systems, the adoption of Bash among network and automation engineers will be just growing. Take care and good bye.
Support us
P.S.
If you have further questions or you need help with your networks, our team is happy to assist you. Just book a free slot with us. Also don’t forget to share the article on your social media, if you like it.
BR,
Anton Karneliuk