
Dear friend,
Being a long-time network engineer, I’ve seen (and done) it all: talking about about IPv6, designing and implementing IPv6 in production service providers and data center networks, holly wars IPv6 vs IPv4, industries saying they aren’t going to use IPv6 ever, and many others. For some network engineers, it could be even quite an “innovation” project (I clearly remember some senior person told me back in 2018 that introduction of IPv6 is an innovation; quite a statement in the 20-years anniversary of IPv6). But today I want to talk about it from a different angle.
How Is Network Relevant for Software?
In many cases every day we rely on the software, which works over Internet: whatever you need to buy or sell some goods, order a table in your favorite cafe, book ticket to train to visit your friends. Connected world is around us and, if for whatever reason it breaks, our life immediately becomes much more difficult. That’s because the applications rely on the Internet and their capability to provide you the service depends on their capabilities to connect from your smartphone or laptop to the application servers. And this capability is significantly affected by the underlying network: whether there is a path through network, whether it is stable, and so on. In other words, the network shall be stable, resilient, and in verifiably working condition. All these things are achievable today through the network automation. We are not saying it is available solely through the automation — surely you can configure things manually via CLI. However, it is achievable solely through the automation within the limited time frame, which is often a key in the current business environment.
As on networks there are so many things depends theses days, ensure you do your networks right: learn network automation:

We offer the following training programs in network automation for you:
- Zero-to-Hero Network Automation Training
- High-scale automation with Nornir
- Ansible Automation Orchestration with Ansble Tower / AWX
- Expert-level training: Closed-loop Automation and Next-generation Monitoring
During these trainings you will learn the following topics:
- Success and failure strategies to build the automation tools.
- Principles of software developments and the most useful and convenient tools.
- Data encoding (free-text, XML, JSON, YAML, Protobuf).
- Model-driven network automation with YANG, NETCONF, RESTCONF, GNMI.
- Full configuration templating with Jinja2 based on the source of truth (NetBox).
- Best programming languages (Python, Bash) for developing automation
- The most rock-solid and functional tools for configuration management (Ansible) and Python-based automation frameworks (Nornir).
- Network automation infrastructure (Linux, Linux networking, KVM, Docker).
- Orchestration of automation workflows with AWX and its integration with NetBox, GitHub, as well as custom execution environments for better scalability.
- Collection network data via SNMP and streaming telemetry with Prometheus
- Building API gateways with Python leveraging Fast API
- Integration of alerting with Slack and your own APIs
- … and many more
Moreover, we put all mentions technologies in the context of real use cases, which our team has solved and are solving in various projects in the service providers, enterprise and data centre networks and systems across the Europe and USA. That gives you opportunity to ask questions to understand the solutions in-depth and have discussions about your own projects. And on top of that, each technology is provided with online demos and labs to master your skills thoroughly. Such a mixture creates a unique learning environment, which all students value so much. Join us and unleash your potential.
Disclaimer
In all the blogs about C, I’m sharing my experience being a software developer, who transitioned into the field from the networking world. It could be not necessary 100% objective, but it shows real working scenarios.
Network and Applications
In the modern world, where everything is connected to each other, starting from client-server applications to distributed applications, message queues, etc, it is crucial to understand how actually applications talking to each other.
Back to Basics: Let’s Recap OSI model
What was one the most foundational topics that you learned in the beginning of the network engineering career? For me it was interconnection models, such as OSI or, more practical one, TCP/IP:
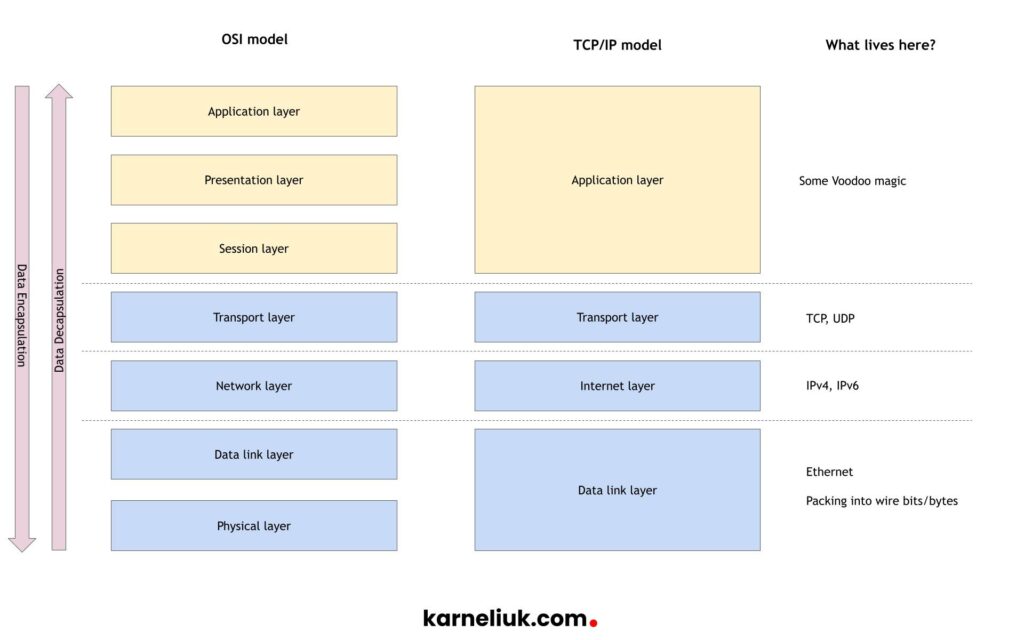
As network engineers, we rarely need to know what happens on the application layer. All we need is to ensure that Ethernet works properly with all the encapsulations, IP addressing and transport information (such as TCP/UDP port). So what’s happening above the transport layer, is often out of interest.
It is a bit ex-aggregation: in many cases network engineers need to understand application layer protocols, such as DNS, HTTP, and others. However, in majority of cases network engineers doesn’t deal with server side of these applications.
We’ll focus on TCP/IP model, as it is simpler to understand and, to be honest, after I’ve started writing my distributed network applications in C, that makes much more sense compared to OSI. So looking on TCP/IP model we can see, that networking ends between application and transport layer (if you don’t see that, you have to believe me). Whenever you connect to your favorite website, your establish a TCP session (as HTTP/HTTPS works over TCP) to a standard HTTP/HTTPS ports (80/TCP, 443/TCP) on a specific IP address of the destination server. And, let’s say, I’m developing some my own application which runs on the very same server, which utilities also TCP protocol. How can I do that, I need to map my application to a different TCP port. Why? Because this is how the server distinguish to which application the traffic is destined. Let’s take a look inside the server running the following applications
- Web server on the port 80/TCP
- Our bespoke application on the port 12345/TCP
- Some other applications, which each Ubuntu Linux runs by default
2
3
4
5
6
7
8
9
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 511 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=4110,fd=6),("nginx",pid=4109,fd=6),("nginx",pid=4108,fd=6),("nginx",pid=4107,fd=6),("nginx",pid=4105,fd=6))
LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=711,fd=14))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=28795,fd=3))
LISTEN 0 511 [::]:80 [::]:* users:(("nginx",pid=4110,fd=7),("nginx",pid=4109,fd=7),("nginx",pid=4108,fd=7),("nginx",pid=4107,fd=7),("nginx",pid=4105,fd=7))
LISTEN 0 32 *:21 *:* users:(("vsftpd",pid=754,fd=3))
LISTEN 0 128 [::]:22 [::]:* users:(("sshd",pid=28795,fd=4))
LISTEN 0 100 0.0.0.0:12345 0.0.0.0:* users:(("server",pid=40433,fd=8))
It is important to run this command with
privileges, as otherwise you won’t see process ID for applications started with different username (e.g., nginx).
The output above is provided by ss (socket statistics) command with flags requesting to show:
- TCP sockets (-t)
- Which are in the listening state sockets (-l)
- Don’t resolve IP addresses to FQDNs and ports to services (-n)
- Show associated process IDs (-p)
If you want to see UDP sockets, use (-u) instead of (-t).
This table actually shows us where there network ends (transport layer protocol and ports) and the application starts (process IDs). It is worth mentioning, that you see above the pair of IP address and port, which particular process is mapped to; however, in many cases the address is 0.0.0.0 (IPv4 wildcard address) or [::] (IPv6 wildcard address). This means that the underlying operating system (Ubuntu Linux in this case) will send to the corresponding process traffic coming on this port on ANY address, which this hosts posses:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s31f6: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
link/ether a0:29:19:47:59:7b brd ff:ff:ff:ff:ff:ff
3: wlp0s20f3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d4:54:8b:78:8a:a2 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.115/24 brd 192.168.1.255 scope global dynamic noprefixroute wlp0s20f3
valid_lft 59977sec preferred_lft 59977sec
inet6 2a01:4b00:beef:cafe:ac00:b2a2:a972:1234/64 scope global temporary dynamic
valid_lft 64211sec preferred_lft 49811sec
5: virbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 52:54:00:df:de:d9 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
6: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc fq_codel master virbr0 state DOWN group default qlen 1000
link/ether 52:54:00:df:de:d9 brd ff:ff:ff:ff:ff:ff
7: vnet0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master virbr0 state UNKNOWN group default qlen 1000
link/ether fe:54:00:6e:b7:e7 brd ff:ff:ff:ff:ff:ff
inet6 fe80::fc54:ff:fe6e:b7e7/64 scope link
valid_lft forever preferred_lft forever
For example, if server receives:
- traffic on IP address 192.168.1.115:12345/tcp, the traffic will be sent to process with id 40433 (which is my application)
- traffic on IP address 192.168.122.1:12345/tcp, the traffic will be sent to the same process with id 40433
Although it is possible to map the process to a specific IPv4 or IPv6 address instead of wildcard mask, it creates extra configuration burden and outside of specific use cases (such as shared hosting) is rarely used.
The last piece of the important information we touch here is the list of applications themselves: to see the particular application speicifed with the process ID, use the following command:
2
3
4
5
6
7
8
9
10
11
12
root 65708 0.0 0.0 55208 1680 ? Ss 18:20 0:00 nginx: master process /usr/sbin/nginx -g daemon on; master_process on;
www-data 65709 0.0 0.0 55840 5612 ? S 18:20 0:00 nginx: worker process
www-data 65710 0.0 0.0 55840 5644 ? S 18:20 0:00 nginx: worker process
www-data 65711 0.0 0.0 55840 5644 ? S 18:20 0:00 nginx: worker process
www-data 65712 0.0 0.0 55840 5616 ? S 18:20 0:00 nginx: worker process
aaa 65852 0.0 0.0 6608 2304 pts/0 S+ 18:29 0:00 grep --color=auto nginx
$ ps aux | grep 40433
anton 40433 0.0 0.0 2364 92 pts/3 S+ 18:37 0:00 ./server
anton 43554 0.0 0.0 9044 2548 pts/2 S+ 19:31 0:00 grep --color=auto 40433
Using “ps aux” command you will get the list of all the running processes, which could be extremely huge; therefore, it is recommended to use filtering with “grep” to shrink the output. Good strategy is to use either application name “users:((“server“,pid=40433,fd=8))” or process id “users:((“server”,pid=40433,fd=8))”.
Linux/Unix Network Socket
Once we observed where network ends and application starts, it is time talk about how it happens. And this is done via network sockets. In a nutshell, socket is a Linux/Unix network interface, which allows the application read data received via network from the network and send data to network. The application makes a system call to Linux kernel to create a socket for a particular address family (e.g., IPv4, IPv6, Unix Path, etc) and protocol (stream – TCP or datagram – UDP) and then, depending on the application side (server or client) it:
- binds the specific address (e.g., distinct or wildcard IPv4/IPv6 address) and listens for incoming messages for servers.
- connects to the server and sends messages for TCP clients, or sends messages without connecting for UDP clients.
This is all super simplified, as in reality there are more actions involved in this process.
All the aforementioned operations are created on top of the created socket, whereas the socket is typically created in C very easily:
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <arpa/inet.h>
int main(int argc, char *argv[])
{
int sockfd;
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0)
{
perror("Error: Cannot create socket");
return 1;
}
return 0;
}
In this snippet we do a few things:
- We instruct the compiler to use content of from headers files (same as import in Python) by using “#include <header_name>” statement, which typically located in “/usr/include/” directory.
- We create main execution function main, which may have arguments (we don’t need them now).
- Finally, we create a socket using socket() command, where we provide 3 mandatory pieces of information:
- Address family:
- AF_INET for IPv4 addresses
- AF_INET6 for IPv6 addresses
- AF_LOCAL for Unix path
- AF_LINK for Ethernet (pure L2) packets
- Type of socket:
- SOCK_STREAM for TCP socket
- SOCK_DGRAM for UDP socket
- Protocol:
- 0 for automatic choice (SOCK_STREAM will pick up TCP and SOCK_DGRAM will pick up UDP)
- 6 for TCP
- 17 for UDP
- Address family:
In this snippet above we amend any useful job, we even don’t bind/listen on the socket
sockfd is a name of the variable with Unix/Linux socket of the integer data type, how we represent it inside our program, which is default name meaning:
- sock – socket
- fd – file descriptor
It is a bit misleading in the beginning, but in reality Linux/Unix socket is a glorified file descriptor (i.e., software abstraction how C interacts with file for read/write). In fact, in the output of the ss command, you see the ID of the socket created by the Linux for this process “users:((“server”,pid=40433,fd=8))”
Multi-protocol IPv4/IPv6 Network Application
Now, as we introduced socket and its structure, you actually see that your application shall know, whether it works over IPv4 or IPv6 at the very beginning, even before we specify the actual IPv4/IPv6 address, we want to map our application to. At a glance, that means that we need to have two independent sockets: one for IPv4 and another for IPv6 to be able to serve both address families; something, like this:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <arpa/inet.h>
int main(int argc, char *argv[])
{
int sockfd4;
if ((sockfd4 = socket(AF_INET, SOCK_STREAM, 0)) < 0)
{
perror("Error: Cannot create socket");
return 1;
}
int sockfd6;
if ((sockfd6 = socket(AF_INET6, SOCK_STREAM, 0)) < 0)
{
perror("Error: Cannot create socket");
return 1;
}
return 0;
}
Then we can use different techniques (e.g., poll() and/or fork()/thread()) to handle both descriptors in an endless loop, which by it looks NGINX does:
2
3
4
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 511 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=4110,fd=6),("nginx",pid=4109,fd=6),("nginx",pid=4108,fd=6),("nginx",pid=4107,fd=6),("nginx",pid=4105,fd=6))
LISTEN 0 511 [::]:80 [::]:* users:(("nginx",pid=4110,fd=7),("nginx",pid=4109,fd=7),("nginx",pid=4108,fd=7),("nginx",pid=4107,fd=7),("nginx",pid=4105,fd=7))
You could notice that each process IDs (e.g., 4110) is associated with both IPv4 socket (file descriptor) 6 and IPv6 socket (file descriptor) 7.
However, this is a deliberate (quite good, to my mind) design choice that application supports both Ipv4 and IPv6 simultaneously. In many cases, though, you would probably run either IPv4 or IPv6, depending on your requirements. However, if you have, write your code in C, you may occasionally (or intentionally) hard -code address family to be IPv4 (AF_INET) or IPv6 (AF_INET6). What are the options you have at your disposal to signal, which address family you want to listen to without a need to re-compile your C code all the time? There are a couple of:
- You can pass address-family as an input (e.g., as Linux environment variable) or inside the configuration file.
- You can create function, which parses the provided address and, say, dynamically determines IPv4 or IPv6 address family based on the IP address string (e.g., if there are “:” characters, then this is IPv6; otherwise, it is IPv4).
This list is not full and we are sure you can come up with a few more ideas.
This approach becomes more complicated though, if you introduce FQDNs. It is less applicable to the server side, but more applicable to the customer, when you tries to connect to your server, as you need to create socket exactly in the same way as on the server side, which includes the specification of the address family before you specify the IP address you want to connect to. Ultimately, when you build connection to your target, you will need to know its IP address; FQDN alone is not enough.
And one more question, say, at some point you will be willing do to listen to IPv4 and IPv6 simultaneously, like NGINX above, but… Is that possible to do that without re-writing your app to listen to 2 sockets?
All those questions we will cover in the next C blog alongside with the full code snippets
Lessons Learned
Coming from the networking world into the software development (network API programming) provides an interesting perspective: it is like finally getting to the top of the TCP/IP model and seeing the end-to-end application flow and all dependencies. Often we hear, we changed something in the application -> it is a network problem. It is a bad joke in the industry, but it shows the real importance of the network, and, sadly, that lack of network knowledge can significantly impact any distributed application, which requires connectivity of its parts placed on different hosts, which arguable is almost any application these days.
At the same time, knowledge of Linux is crucial, as the big focus in network socket programming is actually interacting with Linux kernel. Full stack engineering all the way!
Summary
In this blog post we have outlined the basics of the Linux/Unix network sockets as well as what challenges we face to enable our application to be able to use both IPv4 and IPv6 to communicate between the hosts. We’ve just set the scenery to perform the deep dive into code and demo the nex time. Take care and good bye!
Need Help? Contract Us
If you need a trusted and experienced partner to automate your network and IT infrastructure, get in touch with us.
P.S.
If you have further questions or you need help with your networks, we are happy to assist you, just send us a message. Also don’t forget to share the article on your social media, if you like it.
BR,
Anton Karneliuk




