
Hello my friend,
Recently we’ve been working on an interesting (at least for me) project, which is an MVP of the highly available infrastructure for web services. There are multiple approaches existing to create such a solution including “simply” putting everything in Kubernetes. However, in our case we are building a solution for a telco cloud, which is traditionally not the best candidate for a cloud native world. Moreover, putting it to Kubernetes will require to build a Kubernetes cluster first, which is completely separate magnitude of the problem. Originally we were planning to write this blogpost the last weekend, but it took us a little bit longer to put everything together properly. Let’s see, what we are to share with you.
2
3
4
5
retrieval system, or transmitted in any form or by any
means, electronic, mechanical or photocopying, recording,
or otherwise, for commercial purposes without the
prior permission of the author.
You Are Not Talking about Automation Today, Aren’t You?
Yes, today’s blogpost is dedicated to the network technologies (to a huge mix of different network and infrastructure technologies, to be honest). That’s why there is enough to talk about today without network automation. However, during the course of the blogpost you will see that there overall complexity of the solution is quite high and manual implementation and maintenance of it would be quite laborious. Therefore, we are quite sure, you will be catching yourself thinking, “Oh, this can be probably automated… And that as well”…
And if you do (or especially if you don’t, as that would mean you don’t really get the automation), we are here to help you with the world-class network automation trainings .

We offer the following training programs for you:
- Zero-to-Hero Network Automation Training
- High-scale automation with Nornir
- Ansible Automation Orchestration with Ansble Tower / AWX
- Expert-level training: Closed-loop Automation and Next-generation Monitoring
During these trainings you will learn the following topics:
- Success and failure strategies to build the automation tools.
- Principles of software developments and the most useful and convenient tools.
- Data encoding (free-text, XML, JSON, YAML, Protobuf).
- Model-driven network automation with YANG, NETCONF, RESTCONF, GNMI.
- Full configuration templating with Jinja2 based on the source of truth (NetBox).
- Best programming languages (Python, Bash) for developing automation
- The most rock-solid and functional tools for configuration management (Ansible) and Python-based automation frameworks (Nornir).
- Network automation infrastructure (Linux, Linux networking, KVM, Docker).
- Orchestration of automation workflows with AWX and its integration with NetBox, GitHub, as well as custom execution environments for better scalability.
- Collection network data via SNMP and streaming telemetry with Prometheus
- Building API gateways with Python leveraging Fast API
- Integration of alerting with Slack and your own APIs
- … and many more
Moreover, we put all mentions technologies in the context of real use cases, which our team has solved and are solving in various projects in the service providers, enterprise and data centre networks and systems across the Europe and USA. That gives you opportunity to ask questions to understand the solutions in-depth and have discussions about your own projects. And on top of that, each technology is provided with online demos and labs to master your skills thoroughly. Such a mixture creates a unique learning environment, which all students value so much. Join us and unleash your potential.
Brief Description
So, what have been we were building? Ultimately we have built a highly-available TCP load balancer for non-HTTP traffic. However, in this blogpost we have adapted it to be a load balancer for a web traffic to simplify the explanation.
When we yet chartering the overall solution, we have set for us the following objectives, which we want to achieve:
- Performance. The solution shall be working well not only with a small amount of traffic in lab, but also in the production environment under high load. As such, we were choosing components based on their level of maturity and performance figures available in the industry. Ultimately, TCP load-balancing is not a new class of problems; therefore, it shall be possible to find something stable and performant.
- Open Source. There is a long list of the commercial vendors in the load balancing world: Citrix ADC, F5 Big-IP, A10 Thunder ADC, just to name a few. However, it is also well-known that some hyperscalers and other cloud companies use Open Source technologies for load balancing. Our goal was to figure out what tools they use and how we can leverage them as well.
- High availability. The solution we are designing shall not have any single point of failure (SPOF), what means that outage of any load balancer and/or origin server shall not impact the user traffic. As such, we shall take into account the synchronization of sessions between load balancers (or implement such a type of load balancing where load balancers output will be idempotent (i.e., if we have unchanged set of origin server, the packet flow shall be landing on the same origin server from the same source IP address — remember, we are building TCP load balancer, rather than a pure HTTP, where we can rely on cookies).
- No L2. One of the most popular mechanisms of building HA clusters in any networking component is to implement sort of FHRP (First-Hop Redundancy Protocol), which acts as a heartbeat between devices. By far the most popular tool for such a setup is VRRP, which is supported both in network devices and in Linux. That is precisely what we DON’T WANT. Our aim is to connect each device to a network fabric (both load balancers and origin servers) using its own /31 prefix. The announcement of the virtual IP (VIP) address, which is used to terminate customers traffic shall be done via routing protocol; however, considerations about the speed of convergence shall be done as well, as we are to serve the live customers.
We don’t share the exact metrics in terms of sessions per seconds through the load balancer we want to achieve or the convergence speed, as they are specific to the customer setup. However, we can vaguely say that amount of sessions is high and the convergence time shall be very low.
Solution Description
Components
Data Centre Fabric
The solution we have created was based on L3 VNI functionality of EVPN/VXLAN fabric. It allowed to connect a new load balancing platform as “just another” tenant to the existing data centre. However, mentioned above, our goal was to connect each platforms component using its own independent /31 IPv4 subnet. With such approach, we could connect directly to a routed network and or to EVPN/SR-MPLS/SRv6 or even VPNv4/SR-MPLS/SRv6 network.
The three key requirements for data centre fabric are, therefore:
- Support of L3 VNI
- Support of multiple VRFs for tenant separation
- Quick convergence
As a matter of a fact, any modern data centre network platform can fulfil this requirement. We have chosen for our lab Arista EOS, mainly because we wanted to create a blueprint for EVPN/VXLAN network for another vendor after we did it for Cisco NX-OS recently.
From our experience, Nokia SRLinux and NVIDIA Cumulus Linux will work for such a design good as well.
Load balancing
In general, load balancing is a network device performing specific functionality: terminating customer TCP/UDP session (for HTTP load balancer, it can also terminate SSL session and decrypt the traffic) and establish a new session towards the specific workload (in our case, origin web server). For this functionality we have chosen HAProxy, which is one of the most popular open source load balancers these days. In fact, there is not much alternatives. The only viable one is NGINX. However, from our perspective, the free version is missing important functionality, that is active probing of the origin servers. This functionality is available in NGINX Plus version. Per our objectives we were sticking to Open Source (entirely free components); therefore, we couldn’t use NGINX.
Some further investigations showed that HAProxy is used by Booking.com, GitHub, AirBnB, and Alibaba among others.
One of the key features, which we found in HAProxy is the possibility to have sticky sessions to maintain the connectivity of a specific customer to a specific origin server as well. This feature is claimed to work even in active-active scenario, where different VIPs are active on different load balancers; yet the sessions are shared between HAProxy nodes, so that in the case of failover during an outage or a maintenance, the customer – origin server sessions will be maintaned.
Another component of the load balancer is a routing functionality. HAProxy doesn’t do any routing itself; that’s why we used FRR on the same node to establish a BGP peering with Data Centre fabric to announce VIP for services. To improve convergence we have used BFD, which provides for us a sub-second convergence in case of issues (e.g., server with load balancer becomes unreachable). In the same time, using route-maps we can very tightly control which VIP we are advertise from which load balancer:
- On the hand, we can deploy a classical active/standby approach by announcing from one load balancer all VIPs with long AS_PATH prepend, which is useful for maintenance use cases).
- On the other hand, in peak traffic case we can distribute VIPs between multiple load balancers to make sure we use the full available bandwidth to serve all the customers.
Usage of FRR with BGP and BFD allowed us to eliminate the need of any L2 stretching even between leafs. When the application needs to have a L2 communication, it is possible to run a hypervisor-based overlay with any overlay technology (e.g., SRv6, VXLAN, Geneve, etc).
Origin server
Mainly for our demo purpose to show how load balancers are working, we decided to add origin web servers to the lab, which are based on NGINX. These days NGINX is said to be the most performant and efficient web service and reverse proxy. We admit, in out lab it does nothing but simply serves static content. However, from other projects we have see its power – it is really enormous and in some other blogposts we’ll show some solutions with it.
Topology
Alright, we are all set with the description of the components and the main technologies, let’s see how the sample topology is looking like. First of all, let’s take a look at the physical topology:
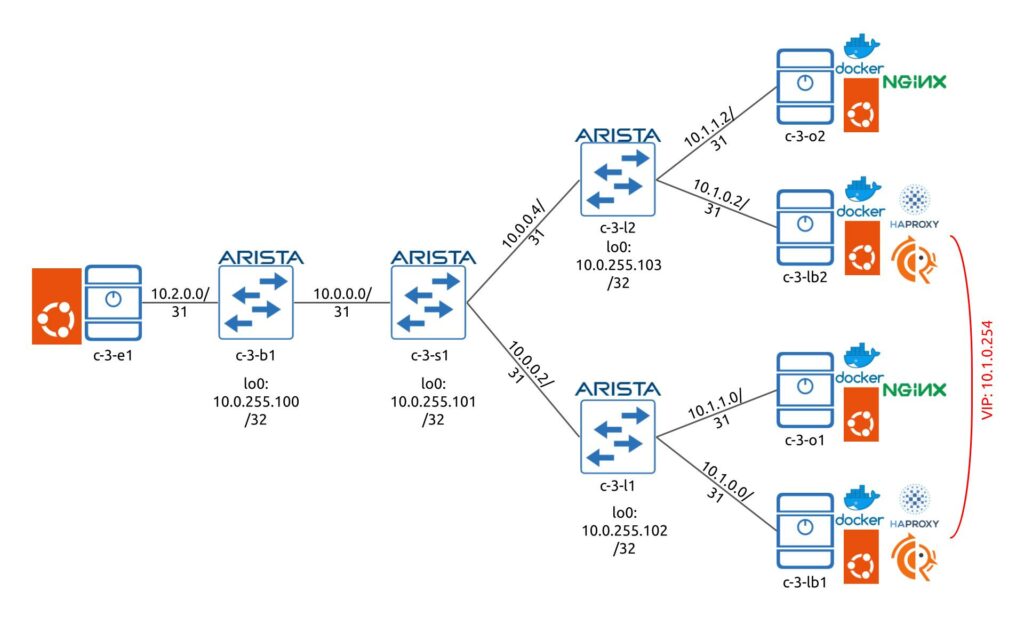
As you can see, there is nothing fancy. We don’t pay much attention to data centre fabric and its resiliency in this specific lab, as we focus on the load balancer.
For the production deployment we have implemented fully resilient CLOS fabric similar to this one, but also relying on Arista fabric.
From the service perspective, the topology is a little bit more interesting:
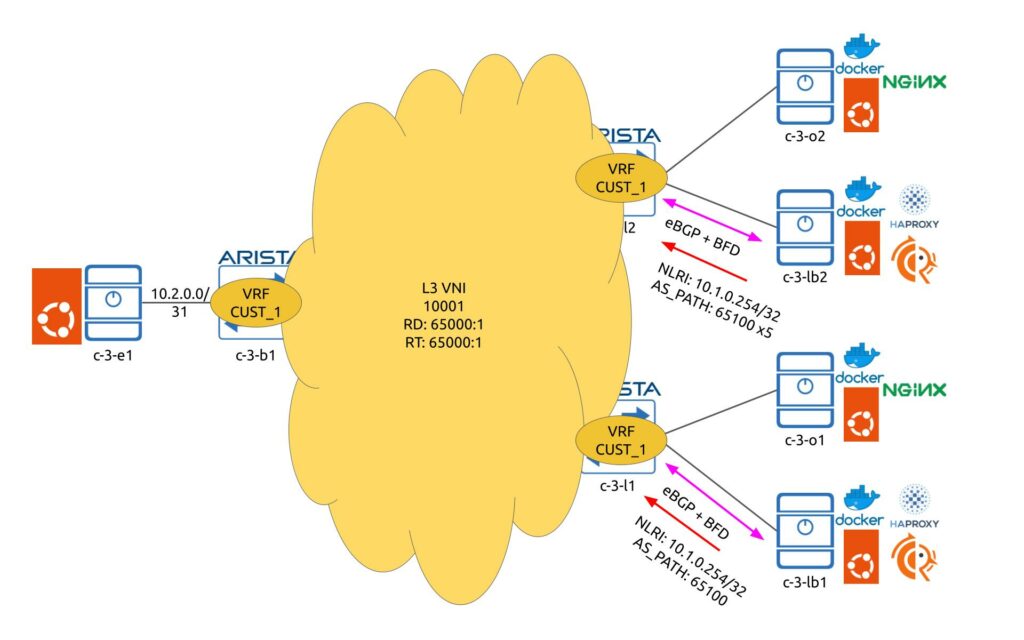
All interfaces from outside the data centre fabric are residing in the customer VRF. All the VRFs share the same RDs and RTs and they also have the same L3 VNI to make sure the hosts can be interconnected. All the interconnect subents are redistributed into BGP and are announced via fabric as Type-5 (ip-prefix) EVPN routes.
From the load balancers connectivity, we have BGP to announce the VIPs. In reality, we even don’t have to receive anything back as we can have simply a static route pointing towards the IP of the leaf. In our case we are reviving only a default route from the fabric. c-3-lb1 is a primary load balancer for VIP 10.1.0.254/32; therefore, it announces it without AS_PATH prepending to the farbic, whilst c-3-lb2 announces it with the AS_PATH prepending with 5 AS to make sure it is not used under the normal circumstances. However, if the route from c-3-lb1 is gone, then route from c-3-lb2 will be propagated through the fabric and it will start attracting the customers traffic.
From origin web servers perspective, there is no need to have any dynamic routing; however, it is required to make sure that there is a connectivity between LBs and origin servers. Such a validation are done via HAProxy configuration so that it periodically (each 2 seconds in our setup, but that can be tuned) checks if it can has a TCP-handshake with each origin server. Each HAProxy runs checks independently one from another.
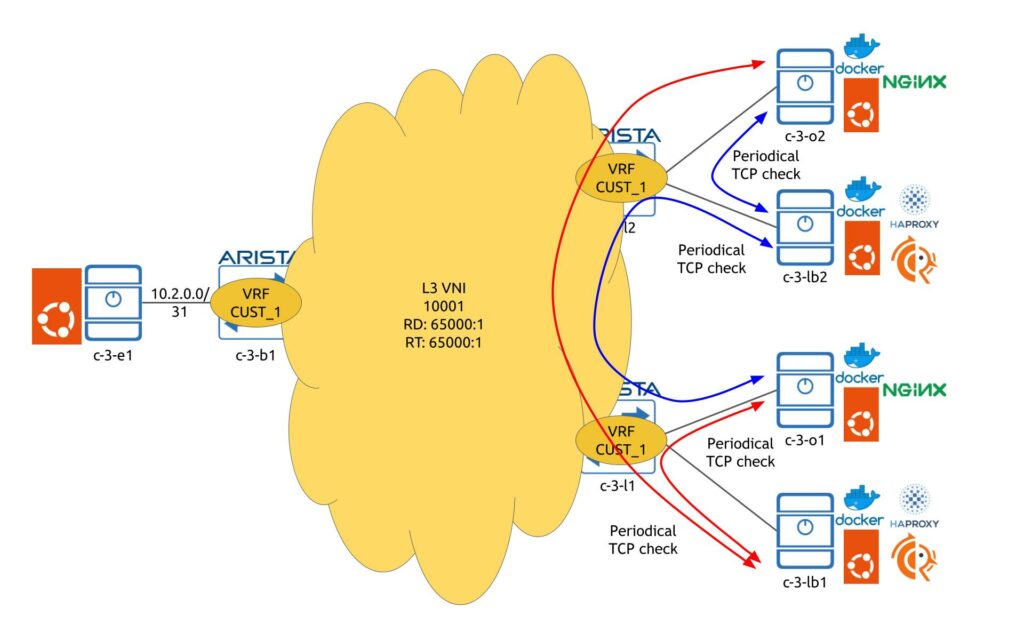
These checks allow to make sure that HAProxy will send traffic only to those origin servers, which are actually responding to the corresponding port (i.e., port where the application is supposed to be running).
Instead of Summary
This is the first part out of two, which describes the setup of the Open Source Load Balancing based on the HAProxy and FRR, which is connected to modern EVPN/VXLAN network run by Arista Networks, and serving content from origin web servers, which are based on NGINX.
In the second part we will go through the configuration and validation snippets. Take care and good bye
Need Help? Contract Us
If you need a trusted and experienced partner to automate your network and IT infrastructure, get in touch with us.
P.S.
If you have further questions or you need help with your networks, we are happy to assist you, just send us a message. Also don’t forget to share the article on your social media, if you like it.
BR,
Anton Karneliuk




